
A few years ago, I was working with Jeff Gee on a system that served models behind a cache. Jeff was trying to launch a new model iteration that showed solid improvements offline but was weak in our A/B tests. After many investigations, he figured out it was due to our cache behaving differently between our control and our treatments. Since I have seen this issue again recently, I thought I would share why serving a model behind a cache can be tricky, and what can be done to mitigate cache related biases.
tl; dr: If you A/B test models that are served behind a cache, make sure to allocate the same traffic percentage to your control and your treatments.
Getting into the weeds
Running machine learning models online is expensive at scale. A popular cost-reduction strategy is to introduce a cache and run the models only when there are cache misses. While straightforward, such a caching strategy can introduce bias in A/B tests experiments when we are not careful about their design.
Let’s assume that we serve results for a million search queries daily and that these queries follow Zipf’s law:
import matplotlib.pyplot as plt
import numpy as np
np.random.seed(42)
n_samples = 1_000_000
samples = np.random.zipf(1.3, n_samples)
# compute the frequency of unique values
_, y = np.unique(samples, return_counts=True)
y[::-1].sort()
# query ranks
x = np.arange(1, len(y) + 1)
# plot the distribution
plt.title("Queries by frequency")
plt.xlabel("Query rank")
plt.ylabel("Frequency")
plt.semilogy()
plt.plot(x, y)
plt.savefig("query_freqs.png")
plt.clf()
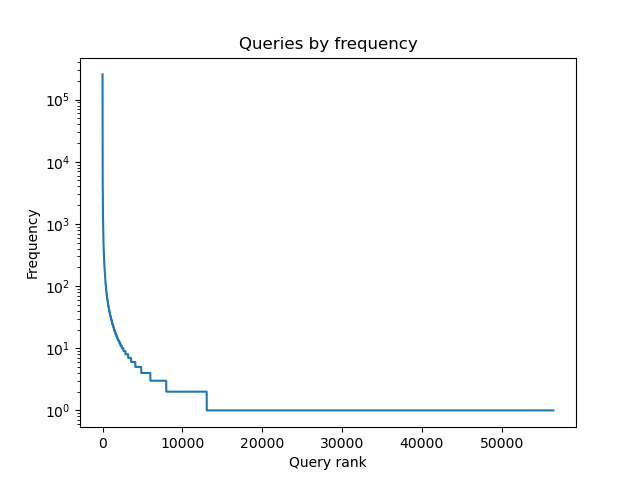
Serving the model behind a cache will allow us to run it only on a fraction of our requests:
cache_miss_rate = len(np.unique(samples)) / len(samples)
print(f"Cache miss rate is {cache_miss_rate:.2%}")
Cache miss rate is 5.65%
When testing a new version of this model using an A/B test, we will need one cache per treatment. Let’s see what happens to our cache miss rate when we allocate 10% of our traffic to a new treatment and keep the remaining 90% for our control:
# control
c_samples = samples[:int(0.9 * len(samples))]
c_miss_rate = len(np.unique(c_samples)) / len(c_samples)
print(f"Control cache miss rate is {c_miss_rate:.2%}.")
# treatment
t_samples = samples[int(0.9 * len(samples)):]
t_miss_rate = len(np.unique(t_samples)) / len(t_samples)
print(f"Treatment cache miss rate is {t_miss_rate:.2%}.")
Control cache miss rate is 5.78%.
Treatment cache miss rate is 9.74%.
The cache miss rate for our treatment is significantly higher than the one for our control! Given that business metrics are often impacted by latency, this may bias our A/B test results.
We can solve this bias by introducing a third treatment that will behave the same as our control model:
# Requests served by the control model that we ignore.
ignored_samples = samples[:int(0.8 * n_samples)]
ignored_miss_rate = len(np.unique(ignored_samples)) / len(ignored_samples)
print(f"Ignored requests cache miss rate is {ignored_miss_rate:.2%}.")
# Requests served by the control model that we use as our baseline
c_samples = samples[int(0.8 * n_samples): int(0.9 * n_samples)]
c_miss_rate = len(np.unique(c_samples)) / len(c_samples)
print(f"Control cache miss rate is {c_miss_rate:.2%}.")
# Requests served by our treatment
t_samples = samples[int(0.9 * n_samples):]
t_miss_rate = len(np.unique(t_samples)) / len(t_samples)
print(f"Treatment cache miss rate is {t_miss_rate:.2%}.")
Ignored requests cache miss rate is 5.96%.
Control cache miss rate is 9.43%.
Treatment cache miss rate is 9.74%.
The cache miss rate for both our control and our treatment are now similar and this new experiment design allows us to test two hypotheses:
- T vs C: Does the treatment improves our metric over our control at comparable cache miss rate?
- C vs ignored: Do cache misses impact our business metrics?
I have seen that (2) is often true. If it is the case for you as well, make sure to always use a control having the same traffic allocation as your treatments.